요약:
cursor = 생오징어(작업 공간)
execute() =오징어 조리 행위(데이터 핸들링)
cursor.execute(sql) = 잘구워진 오징어 완성
cursor.fetch~ = 오징어 다리 떼가는 행위
cursor.fetchone() = 오징어 다리 남아있는거 중에서 한개 떼가기
cursor.fetchmany(숫자) = 오징어 다리 남아있는거 중에서 지정한 갯수만큼 떼가기
cursor.fetchall()=오징어 다리 남아있는거 다 떼가기
일련의 과정이 보기 싫으신분들은 아래 첨부한 스크립트 파일을 수행하면된다.
원래는 phython에서 sql 수행하는 글을 쓰려다 흥미로운 걸 발견해서 쓴다.
테스트 한 데이터는 oracle DB에 기본적으로 있는 emp table 데이터를 이용하였다.

일단 파이선에서 db를 연결하여 커서(DB작업공간이라 생각하면 된다) 까지 구문은 다음과 같다.
#파이선라이브러리 불러오기
import pymysql as pm
import json
#전역 변수 선언부
#DB connection 설정
conn = None
#db cursor 변수
cur = None
#SQL문 변수
sql = ""
#db커넥트 명령어
conn = pm.connect(host="DB주소" ,user="DB아이디" ,password="DB비밀번호" ,db="DB명" ,charset="utf8")
#DB 커서 오픈
cur=conn.cursor()
커서를 열고
이제 sql구문을 넣어 수행을 해보겠다.
sql ="""
SELECT * FROM emp;
"""
#SQL 수행
cur.execute(sql)
끝이다! 그러면 cur란 변수는 우리가 원하는 데이터 형태로 되었을까
print를 해보자
print('커서 타입 출력')
print(type(cur))
print('커서 출력')
print(cur)
print('커서 주소 출력')
print(id(cur))
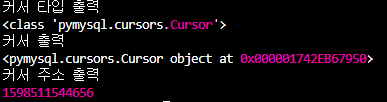
커서타입은 커서이고
커서를 출력하면 메모리상 에 주소가 나온다.

커서는 작업 공간이고 해당 작업공간에 가면 데이터들이 있을것이다.
python은 id라는 함수를 통해 해당 변수의 메모리상의 주소를 확인할수있는데 2번째줄의 '0x000001742EB67950'를 int를 이용해 10진수로 전환하면 동일한 숫자가 나오는 것을 확인할 수 있다.
int("0x000001742EB67950",16)
fetch는 커서를 통해 작업공간을 찾아가 데이터를 떼가는 행위이다.
굳이 비유를 한다면 철수가 자신의 오징어하나를 굽는 것까지가 excute의 행위이고
fetch는 오징어 다리를 다른 친구들 (여기서는 영희, 민수, 주희로 하겠다)에게 나눠주는 행위이다.(변수에 할당)
이제 오징어 다리를 나눠주는 행위를 해보자 (여기서 오징어는 변종이라 다리가 14개라는 가정)
철수는 주희 > 민수 > 영희 순으로 좋아한다. 그래서
영희한테는 오징어다리 1개(fetchone()),
민수한테는 오징어다리 3개(fetchmany(3)),
주희한테는 남은 오징어다리를 다준다 가정하자(fetchAll())
case 1) 오징어 다리를 영희 ☞ 민수 ☞ 주희 순으로 주었을 경우
이경우는
fetchone() ☞ fetchmany(3) ☞ fetchall()
순서로 실행되는 것이다 한번 결과를 출력해볼까?
#커서에서 sql을 수행한 결과를 붙여넣기
dataOne=cur.fetchone()
dataSetSome = cur.fetchmany(3)
dataSet = cur.fetchall()
print('# 1개의 갯수 출력')
print(dataOne)
print('# 일부 갯수 출력')
print(len(dataSetSome))
print('# 일부 데이터 출력')
print(dataSetSome)
print('# 나머지 데이터 갯수 출력')
print(len(dataSet))
print('# 나머지 데이터 출력')
print(dataSet)

# 1개의 갯수 출력
(7369, 'SMITH', 'CLERK', 7902, datetime.date(1980, 12, 17), Decimal('800.00'), None, 20)
# 일부 갯수 출력
3
# 일부 데이터 출력
(
(7499, 'ALLEN', 'SALESMAN', 7698, datetime.date(1981, 2, 20), Decimal('1600.00'), Decimal('300.00'), 30),
(7521, 'WARD', 'SALESMAN', 7698, datetime.date(1981, 2, 22), Decimal('1250.00'), Decimal('500.00'), 30),
(7566, 'JONES', 'MANAGER', 7839, datetime.date(1981, 4, 2), Decimal('2975.00'), None, 20)
)
# 나머지 데이터 갯수 출력
10
# 나머지 데이터 출력
(
(7654, 'MARTIN', 'SALESMAN', 7698, datetime.date(1981, 9, 28), Decimal('1250.00'), Decimal('1400.00'), 30),
(7698, 'BLAKE', 'MANAGER', 7839, datetime.date(1981, 5, 1), Decimal('2850.00'), None, 30),
(7782, 'CLARK', 'MANAGER', 7839, datetime.date(1981, 6, 9), Decimal('2450.00'), None, 10),
(7788, 'SCOTT', 'ANALYST', 7566, datetime.date(1987, 4, 19), Decimal('3000.00'), None, 20),
(7839, 'KING', 'PRESIDENT', None, datetime.date(1981, 11, 17), Decimal('5000.00'), None, 10),
(7844, 'TURNER', 'SALESMAN', 7698, datetime.date(1981, 9, 8), Decimal('1500.00'), Decimal('0.00'), 30),
(7876, 'ADAMS', 'CLERK', 7788, datetime.date(1987, 5, 23), Decimal('1100.00'), None, 20),
(7900, 'JAMES', 'CLERK', 7698, datetime.date(1981, 12, 3), Decimal('950.00'), None, 30),
(7902, 'FORD', 'ANALYST', 7566, datetime.date(1981, 12, 3), Decimal('3000.00'), None, 20),
(7934, 'MILLER', 'CLERK', 7782, datetime.date(1982, 1, 23), Decimal('1300.00'), None, 10)
)
데이터를 보면 알겠지만 겹치는게 없다. 기존 emp 데이터를 생각하면 패치 작업이 이렇게 된것이다.

우선 fetchone()되어 1번 데이터가 들어간 공간이 완성되었고
fetch가 되지 않은 나머지 애들중에서 fetchmany(3)을 하여 2번이 들어간 공간 완성되었다.
나머지 데이터는 fetchall()로 인하여 3번데이터가 들어간 공간이 완성되었다.
슬슬 감이 올것이다.
만약에 순서를 바꿔서 출력한다면 어떨까?
case 2) 오징어 다리를 민수 ☞ 영희 ☞ 주희 순으로 주었을 경우
이경우는
fetchmany() ☞fetchone() ☞ fetchall()
########################CASE2 순서를 바꿔서 출력한다면?
cur=conn.cursor()
sql ="""
SELECT * FROM emp;
"""
#SQL 수행
cur.execute(sql)
print(type(cur))
#커서에서 sql을 수행한 결과를 붙여넣기
dataSetSome = cur.fetchmany(3)
dataOne=cur.fetchone()
dataSet = cur.fetchall()
print('## fetchone() 데이터 출력')
print(dataOne)
print('# fetchmany() 갯수 출력')
print(len(dataSetSome))
print('## fetchmany() 데이터 출력')
print(dataSetSome)
print('# fetchAll() 갯수 출력')
print(len(dataSet))
print('## fetchAll() 데이터 출력')
print(dataSet)
#데이터 타입 출력
print(type(dataSetSome))
cur.close()
결과
## fetchone() 데이터 출력
(7566, 'JONES', 'MANAGER', 7839, datetime.date(1981, 4, 2), Decimal('2975.00'), None, 20)
# fetchmany() 갯수 출력
3
## fetchmany() 데이터 출력
(
(7369, 'SMITH', 'CLERK', 7902, datetime.date(1980, 12, 17), Decimal('800.00'), None, 20),
(7499, 'ALLEN', 'SALESMAN', 7698, datetime.date(1981, 2, 20), Decimal('1600.00'), Decimal('300.00'), 30),
(7521, 'WARD', 'SALESMAN', 7698, datetime.date(1981, 2, 22), Decimal('1250.00'), Decimal('500.00'), 30))
# fetchAll() 갯수 출력
10
## fetchAll() 데이터 출력
(
(7654, 'MARTIN', 'SALESMAN', 7698, datetime.date(1981, 9, 28), Decimal('1250.00'), Decimal('1400.00'), 30),
(7698, 'BLAKE', 'MANAGER', 7839, datetime.date(1981, 5, 1), Decimal('2850.00'), None, 30),
(7782, 'CLARK', 'MANAGER', 7839, datetime.date(1981, 6, 9), Decimal('2450.00'), None, 10),
(7788, 'SCOTT', 'ANALYST', 7566, datetime.date(1987, 4, 19), Decimal('3000.00'), None, 20),
(7839, 'KING', 'PRESIDENT', None, datetime.date(1981, 11, 17), Decimal('5000.00'), None, 10),
(7844, 'TURNER', 'SALESMAN', 7698, datetime.date(1981, 9, 8), Decimal('1500.00'), Decimal('0.00'), 30),
(7876, 'ADAMS', 'CLERK', 7788, datetime.date(1987, 5, 23), Decimal('1100.00'), None, 20),
(7900, 'JAMES', 'CLERK', 7698, datetime.date(1981, 12, 3), Decimal('950.00'), None, 30),
(7902, 'FORD', 'ANALYST', 7566, datetime.date(1981, 12, 3), Decimal('3000.00'), None, 20),
(7934, 'MILLER', 'CLERK', 7782, datetime.date(1982, 1, 23), Decimal('1300.00'), None, 10)
)단지 시행 순서만 바꿨을뿐인데 변수 dataOne과 dataSetSome에 할당된 데이터들이 달라졌다.

우선 fetchSome(3)이 먼저 데이터를 할당받았기에 2번데이터가 들어가고
fetchone()은 그다음 3개이후에 1개값을 할당받는다.
그리고 fetchall()은 이전과 동일하게 할당받았다.
그렇다면 fetchall부터 수행한다면 어떻게 될까?
case 3) 오징어 다리를 주희☞ 민수☞ 영희 순으로 주었을 경우
fetchall() ☞fetchmany() ☞ fetchone()
########################CASE2 fetchall부터 수행한다면ㄴ?
cur=conn.cursor()
sql ="""
SELECT * FROM emp;
"""
#SQL 수행
cur.execute(sql)
print(type(cur))
#커서에서 sql을 수행한 결과를 붙여넣기
dataSet = cur.fetchall()
dataSetSome = cur.fetchmany(3)
dataOne=cur.fetchone()
print('### 1개의 데이터 출력')
print(dataOne)
print('### 일부 데이터 출력')
print(dataSetSome)
print('### 모든 데이터 출력')
print(dataSet)
#데이터 타입 출력
print(type(dataSetSome))
cur.close()
### fetchone() 출력
None
### fetchmany()데이터 출력
()
### fetchAll()
((7369, 'SMITH',
'CLERK', 7902, datetime.date(1980, 12, 17), Decimal('800.00'), None, 20),
(7499, 'ALLEN', 'SALESMAN', 7698, datetime.date(1981, 2, 20), Decimal('1600.00'), Decimal('300.00'), 30),
(7521, 'WARD', 'SALESMAN', 7698, datetime.date(1981, 2, 22), Decimal('1250.00'), Decimal('500.00'), 30),
(7566, 'JONES', 'MANAGER', 7839, datetime.date(1981, 4, 2), Decimal('2975.00'), None, 20),
(7654, 'MARTIN', 'SALESMAN', 7698, datetime.date(1981, 9, 28), Decimal('1250.00'), Decimal('1400.00'), 30),
(7698, 'BLAKE', 'MANAGER', 7839, datetime.date(1981, 5, 1), Decimal('2850.00'), None, 30),
(7782, 'CLARK', 'MANAGER', 7839, datetime.date(1981, 6, 9), Decimal('2450.00'), None, 10),
(7788, 'SCOTT', 'ANALYST', 7566, datetime.date(1987, 4, 19), Decimal('3000.00'), None, 20),
(7839, 'KING', 'PRESIDENT', None, datetime.date(1981, 11, 17), Decimal('5000.00'), None, 10),
(7844, 'TURNER', 'SALESMAN', 7698, datetime.date(1981, 9, 8), Decimal('1500.00'), Decimal('0.00'), 30),
(7876, 'ADAMS', 'CLERK', 7788, datetime.date(1987, 5, 23), Decimal('1100.00'), None, 20),
(7900, 'JAMES', 'CLERK', 7698, datetime.date(1981, 12, 3), Decimal('950.00'), None, 30),
(7902, 'FORD', 'ANALYST', 7566, datetime.date(1981, 12, 3), Decimal('3000.00'), None, 20),
(7934, 'MILLER', 'CLERK', 7782, datetime.date(1982, 1, 23), Decimal('1300.00'), None, 10))

얄짤 없다 14개다 한 변수에 들어가고 나머지애들은 데이터 못얻었다.
하다가 신기해서 작성해봤다.
파일도 올려놨으니 참조 바란다.
참조한 사이트
https://acdongpgm.tistory.com/174
[SQL] Python 에서 SQL을 다루는 방법.
1. Python에서 데이터베이스에 연결하는 법 import sqlite3 # built-in library (Python 2.x & 3.x) dbpath = "chinook.db" conn = sqlite3.connect(dbpath) cur = conn.cursor() Python에서 SQL을 사용할 때에는 먼저 db와 연결해주는 connec
acdongpgm.tistory.com
https://stackoverflow.com/questions/50625183/unpack-tuple-within-sql-statement
Unpack tuple within SQL statement
I am using Python and PyMySQL. I want to fetch a number of items from a MySQL database according to their ids: items_ids = tuple([3, 2]) sql = f"SELECT * FROM items WHERE item_id IN {items_ids};"...
stackoverflow.com
emp,dept create 스크립트 (mysql기준)
EMP, DEPT 실습용 테이블
본 포스팅은 MySQL 8.0.23 버전을 사용중이며, 툴은 Toad for MySQL 8.0 사용 중 입니다. CREATE TABLE dept ( deptno int NOT NULL AUTO_INCREMENT, dname varchar(20) , loc varchar(20) , CONSTRAINT pk_dept PRIMARY KEY ( deptno ) ) engine=InnoDB
bbinya.tistory.com
'프로그래밍 > Python' 카테고리의 다른 글
| pickle.UnpicklingError: invalid load key (완전 성공 아님) (0) | 2022.11.07 |
|---|
